

ホームページ運営している方で、製品数が多すぎて目標とする製品ページにユーザーがなかなかたどり着けないという悩みを抱えている企業様は多いのではないでしょうか。
サイトに検索機能を追加したいが、価格帯が合わず断念した会社様も多いと思います。
しかし近年、生成AIによるチャットボットやAI検索というソリューションが登場してきました。
この記事では、サイト内検索でお悩みの企業様向けに、生成AIによるチャットボットや検索がどこまで使えるのかという観点で調べてみました。
- これまでの企業向けチャットボットと「検索型AI」が注目される理由
- 1-1.企業向けチャットボットのこれまで:FAQ自動化とその限界
- 1-2.ChatGPT登場と「AIチャットボット」の誤答リスク
- 1-3.検索型AIの登場:ChatGPTの長所を活かしつつ誤答を防ぐ
- 生成AI検索の仕組みとデータの流れ
- 2-1.RAGのデータ保存場所・処理の流れ
- 2-2.よくある誤解:ChatGPTに「学習される」?
- まず揃えるべき最低限のコンテンツは?
- 3-1.コンテンツの種類と目安
- 3-2.注意すべきファイル形式と文字情報
- 3-3.情報の整理とカテゴライズ
- おすすめのツールとその特性(ノーコード・日本語対応)
- 4-1.Chatbase:一番手軽な導入ツール
- 4-2.SiteGPT:検索型に近い精度重視型
- 4-3.CustomGPT.ai:品質最重視のチャットボット
- 4-4.ツール選定の際に見るべきポイント
- 社内の情報管理体制とガイドラインの整備
- 導入後のチェックポイントと改善サイクル
- 6-1.利用ログの収集と分析
- 6-2.無回答・誤解ログをもとに改善する
- 6-3.一定の回答精度に達したら「限定チャット」を「公開」へ
- まとめ
1.これまでの企業向けチャットボットと「検索型AI」が注目される理由
1-1.企業向けチャットボットのこれまで:FAQ自動化とその限界
企業のカスタマーサポートや社内ヘルプデスクの効率化手段として、「チャットボット」は以前から注目されてきました。
特にB2B分野では、限られた人員で業務を回す必要があることから、「よくある質問(FAQ)」に自動で答えてくれるチャットボットは、問い合わせ対応の負担軽減に大きく貢献してきました。
これまでのチャットボットの多くは、「ルールベース型」と呼ばれる仕組みに基づいています。これは、あらかじめ想定される質問とそれに対応する回答をペアで登録し、ユーザーからの質問文に含まれるキーワードや定型表現にマッチした場合に、対応する回答を提示するという方式です。
この方式は、問い合わせ内容があらかじめ想定できるケースや回答が定型的で変更の少ない業務(例:営業時間の確認、申請書類の取得方法など)においては有効でした。
しかし、限界も明らかになっています。例えば以下のようなケースです。
(1)ユーザーの表現が想定外だと答えられない
ルールベース型のチャットボットは、自然言語の多様な言い回しや表現の揺れに弱いです。たとえば、「送料はいくらですか?」という質問には対応していても、「配送費用はどれくらい?」のような表現ゆれには対応できず、「該当する回答が見つかりません」と返されることも少なくありません。このような表記のゆれに対応しようとすれば、辞書を作り込まなくてはなりませんでした。
(2)カバー範囲が狭く、複雑な質問に対応できない
ルールベースで対応できるのは、一定のシナリオに沿った「1問1答」のような単純なやり取りが中心です。複数条件が絡む質問や特定の状況にのみ対応する問い合わせにはうまく対応できません。
たとえば、「海外からの注文で、法人宛に請求書が欲しい場合にどんな支払方法があるのですか?」といった複合的な質問には、海外からの注文かどうかを判断し、次に誰宛に請求書が欲しいのか、という個別に分岐のルールを設けなければ対応できません。やりとりが冗長になり、ユーザーが途中で問い合わせを諦めたり、オペレーターへの転送が頻発するという結果になりがちです。
(3)導入・運用に手間と属人性が伴う
ルールベースのチャットボットは、シナリオの作成や定期的な更新が必要です。FAQが増えるたびにルールを追加し、文言の微調整や分岐のロジックを設計し直す必要があります。
このような作業はしばしば属人的になり、担当者が交代した際に「ブラックボックス化」してしまう例も見受けられます。
特に中小企業や1名体制のマーケティング担当者では、チャットボットを運用する負荷に耐えきれず、やがて放置されてしまうケースも少なくありません。
こうした要因が重なって、「チャットボットは導入したが思ったより使えない」「誤回答が多く、結局人手での対応が必要」といった悩みを抱える企業も多いです。
以上はチャットボットを導入する側の事情でしたが、では利用者側はチャットボットを使っているのでしょうか。
残念ながら2025年現在、利用率はそれほど高くはありません。
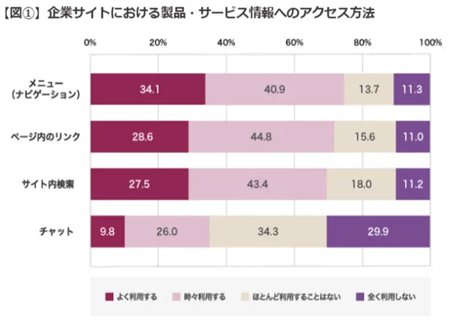
出典:【Web担】BtoBサイトの評価、3年連続で「三菱電機(FA)」がトップ死守。
評価のカギは?【トライベック調べ】
大規模サイトの利用者7700人がこのアンケートに参加していますが、チャットをよく利用すると回答した人は10%に満たない状況です。
これはチャットをしても自分の目指す回答を得られなかったからという理由が大きいのではないかと推定できます。
チャットボットへの期待が大きい割に、機能が追いついていない様子が伺えます。
1-2.ChatGPT登場と「AIチャットボット」の誤答リスク
ChatGPTをはじめとする生成AIの普及により、チャットボットの可能性は大きく変化しました。
従来のルールベース型とは異なり、生成AIは事前に用意されたシナリオに依存せず、自然な対話や柔軟な応答を生成することができるようになったのです。
ユーザーはより人間らしいインタフェースで情報を得られるようになり、問い合わせの満足度向上や業務効率化への期待が一気に高まりました。
しかし、同時に顕在化したのが「誤答」リスクで、いわゆる「ハルシネーション(幻覚)」と呼ばれる問題です。過去に学習した膨大なデータに基づいて「もっともらしい答え」を回答してくれますが、リアルタイムの正確性や出典表示を保証してくれません。
自社特有の商品名や社内用語に関する質問、法制度や契約条項など、文言の正確性が求められる分野、PDFやWebページなどにしか掲載されていない製品の最新情報等の場合は、明らかに問題になります。
例えば、AIチャットボットが利用者に対して、誤って旧型モデルの仕様を案内してしまっては困るわけです。
1-3.検索型AIの登場:ChatGPTの長所を活かしつつ誤答を防ぐ
こうした課題を受けて注目されているのが、「検索型AI」という新しいアプローチです。
これは、ChatGPTのような人間らしい自然な会話をしながらも、自社が管理するFAQやマニュアル、PDFなどの一次情報をベースに回答する仕組みです。
この検索型AIの多くは、近年注目されている「RAG(Retrieval-AugmentedGeneration)」というアーキテクチャに基づいています。RAGは、以下のような流れで動作します。
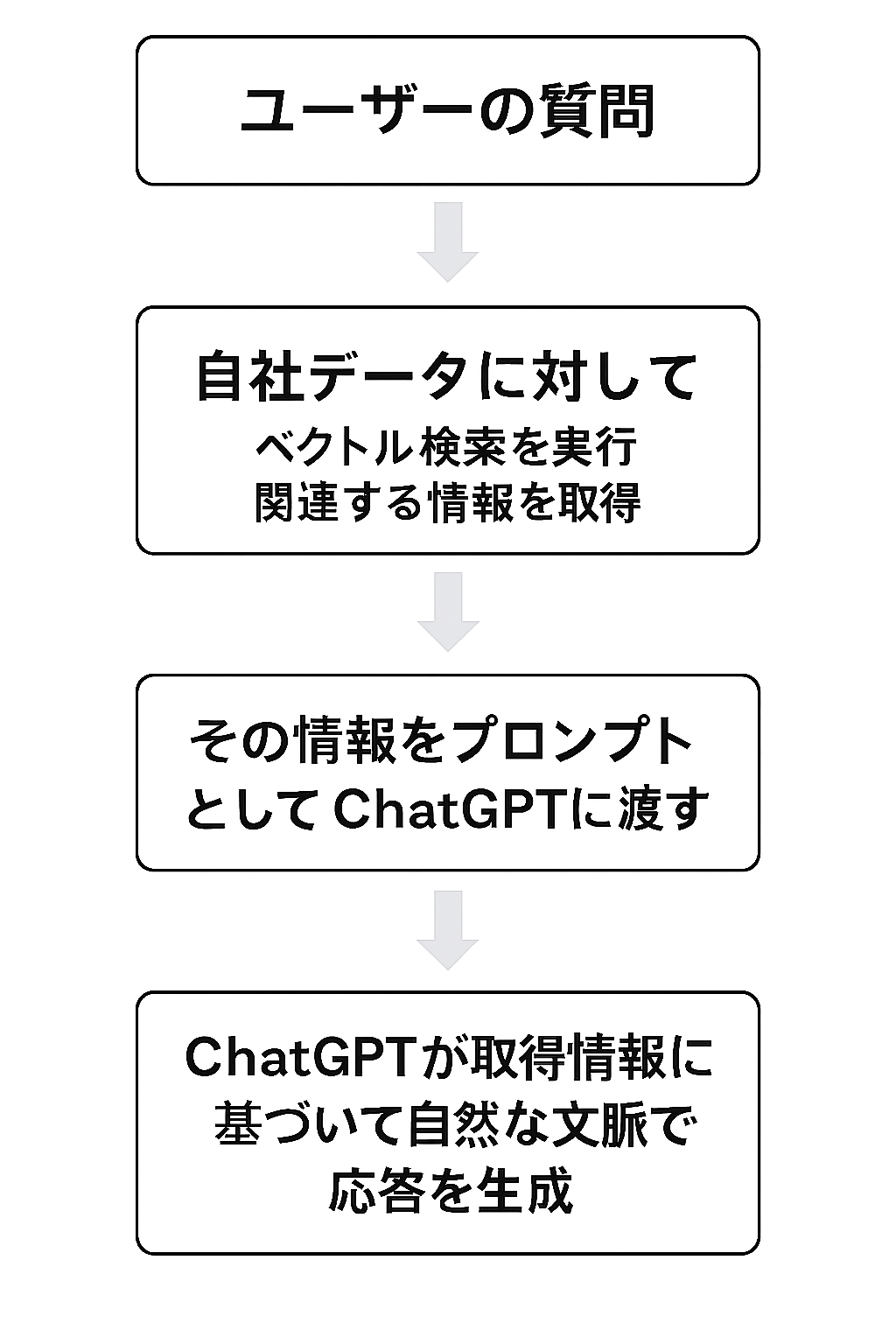
この仕組みによって、生成AIが出力する内容は「自社が提供した情報の範囲内」に限定されるため、誤答やハルシネーションのリスクが大幅に低減されます。
また、多くのツールでは「この回答は◯◯のPDFの3ページをもとにしています」のように、出典の明示も可能です。
以下のような情報を扱うサイトにおいては、検索型AIは非常に相性が良いです。
- 誤回答が致命傷になりうる(法令、仕様、納期などの誤案内)
- 過去資料(PDF、ナレッジ、FAQ)が多数存在する
- 製品数や用語が多く、顧客が目的ページに辿り着きにくい
例えば、製品ラインナップが数百種類ある製造業で、従来のキーワード検索では「該当ページが出ない」といった場合でも、検索型AIであれば、製品名が曖昧でも、意味的に近い情報を検索できるため、目的ページに辿り着きやすく、コンバージョンへの導線を維持しやすくなります。
では、この検索型AIの中核をなす「RAG」という仕組みについて、「なぜ安全なのか」「どこに情報が保存されるのか」について、さらに詳しく解説していきます。
2.生成AI検索の仕組みとデータの流れ
ここでは、RAGの全体構造と、企業ユーザにとって最も気になるデータの保存場所、セキュリティリスク、OpenAIへの学習問題などについて、図を交えてわかりやすく解説します。
2-1.RAGのデータ保存場所・処理の流れ
まず、生成AI検索ツールがどのようにして「ユーザーの質問に答えるか」ですが、簡略化すると以下のような流れになります。
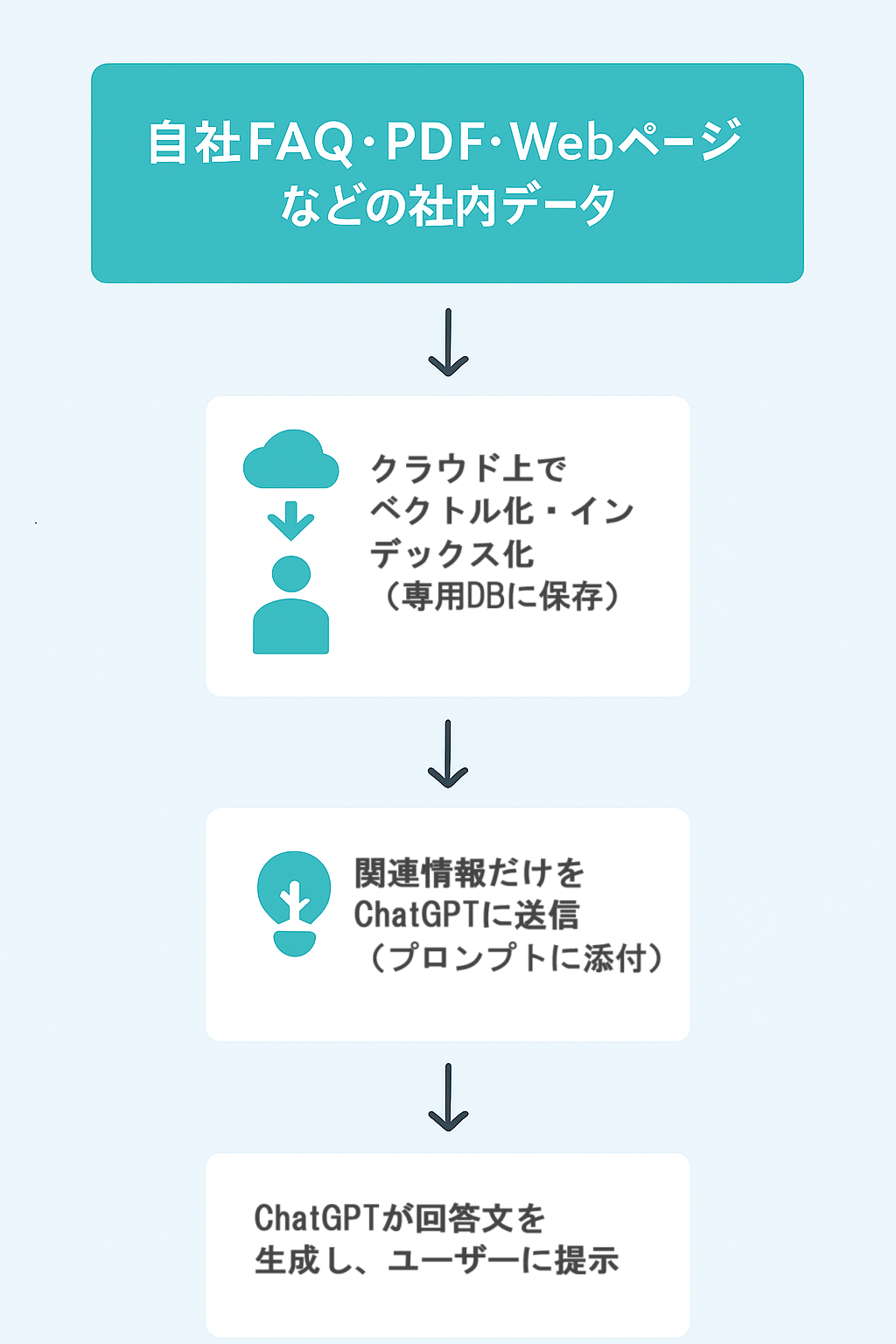
各ステップの処理概要とセキュリティ
1.データのベクトル化・インデックス化
自社でアップロードしたドキュメント(PDF、Webページ、Wordなど)は、自然言語を意味ベースで数値化する「ベクトル変換」が行われます。その後、クラウド上の専用データベース(多くはGCPまたはAWS)にインデックスとして保存され、検索対象になります。
ベクトル変換とは、簡単に言うとテキストや画像などを、ニューラルネットワークなどのモデルを用いて数値に変換する技術です。
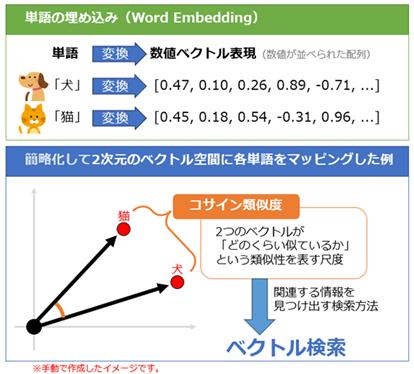
出典:ITMedia「ベクトル検索(Vector Search)とは? キーワード検索との違い」
ChatGPT等に代表される大規模言語モデルは、単語だけでなく、その単語が使われている文の流れや前後関係を大量に学習しています。例えば
「ふじさんは日本一高い山です。」
「富士山は登山者に人気です。」
「Mt.Fujiは観光スポットです。」
こういう文を何百万回も読んでいるので、「富士山」「ふじさん」「Mt.Fuji」は似たような意味をもつと理解しています。同じような使われ方をする単語は、同じ意味を持つとみなされ、ベクトル化する際に「似た意味」は近い位置に配置されます。
たとえば「富士山」と「ふじ山」のような言い換えや表記ゆれも、最終的には似た方向のベクトルとして表現されます。
2.ユーザーの質問に対する処理
ユーザーが自然文で質問すると、AIはその文をベクトル化して、上記のインデックスから意味的に近い情報を数件ピックアップします。この関連情報が、ChatGPTへのプロンプトの一部として使われます。
自然な文章の生成処理そのものは、クラウド上の専用データベースからAPI経由でChatGPT(もしくは同等のLLM)に依頼されます。この関連情報とプロンプトを基に、ChatGPTはユーザへ回答を返します。
2-2.よくある誤解:ChatGPTに「学習される」?
多くの企業担当者が誤解しているのが、「アップロードしたPDFがChatGPTに学習されてしまうのでは?」という懸念です。が、結論から言えば、そんなことはありません。
ここで重要なのは「自社データがChatGPTに学習されるわけではない」という点です。
データ保存先が、各サービスのクラウドであることにご注目ください。
また、自社データは外部APIを通じて送信されます。
OpenAIのAPIの公式仕様において、「ユーザーの入力やカスタムデータは、明示的に同意しない限り学習には使用されない」ことが明記されています。ChatbaseやSiteGPTといったサービスも、このポリシーを尊重して設計されています。2024年2月ごろの開発者フォーラムでのやりとりで、API経由の入力データは学習に使われないという点が裏付けられています。
企業がアップロードした情報は、一時的な参照として使われるだけであり、ChatGPTや他のモデルの学習データに組み込まれることはありません。
この点は、OpenAIのプライバシーポリシーと同じく、主要な生成AI検索ツール提供会社のプライバシーポリシーに明記されています。
セキュリティ・ガバナンス観点での留意点があるとすれば、社内機密を扱う場合には、生成AI検索ツールベンダーがどのクラウドサービスを利用しているか(例:米国のAWS、EU拠点のGCPなど)です。
もう一つ、学習オプトアウトの機能の有無は確認すべきでしょう。
AIサービスの中には、「ユーザーが同意しないと学習に使わない」と宣言しているものもあれば、逆に「特に設定しなければ勝手に学習される」というものも存在します。
明示的に「学習されない」ポリシーかどうか、明記されていない場合、管理画面などから「オプトアウト申請」が設定可能かどうかは、運用上重要な問題です。
3.まず揃えるべき最低限のコンテンツは?
生成AIを活用した「検索型AI」やAIチャットボットを導入する際に、最初に悩むのはどのくらいの社内コンテンツを用意すべきか?という点です。リソースをかけすぎず、現実的な範囲でスタートする必要があります。
ここでは、検索AIの精度を高め、ユーザーからの質問に的確に応答するために必要な最低限のドキュメント量と種類について整理します。
3-1.コンテンツの種類と目安
検索型AIサービス(例:Chatbase、CustomGPT.aiなど)の実際のPoCや導入事例から見た、AIが「文脈を理解しやすく」「誤答を抑えやすい」水準として、最低限推奨されているコンテンツの目安は以下の通りです。
ただし、これら全てを集めれば完全な検索AIができるという意味ではありません。
テスト的に始めるのには、最低これぐらいのデータが必要だという理解の方が適切です。
| 種別 | 必要量(目安) | 内容 |
| FAQ(質問+回答) | 20~30項目 | よくある問い合わせ、導入方法、仕様など |
| 固定ページ | 10~30ページ | サービス紹介、料金体系、サポート案内など |
| PDF資料 | 2~5点(1万~3万字) | 取扱説明書、カタログ、導入事例など |
| ファイル形式 | PDF(テキスト抽出可能)、Word、HTML | スキャン画像PDFは不可。OCRでテキスト化を推奨 |
3-2.注意すべきファイル形式と文字情報
生成AI型の検索は、ベクトル検索による意味的な一致を実現するため、アップロードしたドキュメントからテキスト情報を抽出できることが大前提です。
WordファイルやHTML、Googleドキュメントは読み取り可能な場合が多いですが、印刷会社が製作した製品カタログやリーフレット類は、画像のみの資料が多く、テキストで読み取れない場合も多いです。
このような場合は、OCRソフトやPDF変換ツールを併用してAIに正しく認識させるための事前の準備が必要になります。
「PDF内のテキストがコピペ可能か?」「文字検索できるファイルか?」等キーワード検索できる文書かどうか必ず確認してください。
3-3.情報の整理とカテゴライズ
生成AI検索では、コンテンツ量だけでなく、整理の仕方も検索精度に大きく影響します。
分類やタグ付けがされていないデータでは精度が落ちやすいです。手元にある資料をアップロードするときに、分類・タグ付けすることで、関連情報の抽出率が上がり、誤答を避けやすくなります。
例えば、以下のようにフォルダ名やファイル構造を整えるだけで、検索型AIが情報の構造を理解しやすくなります。
①フォルダごとに分類し、フォルダにわかりやすい名称をつける
例:
/faq_製品A/:製品Aに関するよくある質問と回答
/manual_設定/:導入設定に関するマニュアル
/support_トラブル対応/:カスタマーサポート向け資料
②同じフォルダ内のファイルも、できれば目的別に命名する
例:
faq_導入手順.pdf`
manual_初期設定ガイド.docx`
support_エラー対応一覧.xlsx`
フォルダ構成をそのままアップロードできるかどうかは、生成AIのサービス毎に異なります。フォルダ単位でアップロード可能なツールもあります。
なぜここまで手間をかけなければいけないのでしょうか?
理由は、分類されていない情報は、AIにとって「その情報は使える関係性が不明」な状態となります。
AIが、アップロードされたコンテンツを正しく認識できるように、ファイルの命名規則を工夫し、整理する必要があります。構造化されたフォルダと命名規則があるだけで、利用者が入力した質問に対する関連性を判断しやすくなり、正しい文書が選ばれやすくなります。
この表に見るように、使いやすい生成AI検索を作るには、比較的小さなボリュームのデータを揃えれば始めることができます。そして、少量でも分かりやすく分類された情報であれば、高精度な検索は実現可能と言われています。
問い合わせ頻度の高い分野に限って着手し、有益な生成AIのナレッジベースを作ることができれば、問い合わせ件数を短期間に40%減らすことは可能だという試算もあります。
そのためには生成AIが、アップロードしたドキュメントを正確に理解し活用できるかどうかがポイントです。
地味ではありますが、AI活用の第一歩は、社内情報の整備です。これは、そのまま営業やサポートの効率化にもつながります。
4.おすすめのツールとその特性(ノーコード・日本語対応)
生成AIを活用したサイト内検索やチャットボットを導入する際、使いやすいツールを選ぶことは成功の鍵です。
特に、ノーコードで導入でき、日本語にも対応しているツールは、中小企業や一人情シス、ソロ運営者にとって有力な選択肢です。
ここでは、山ほどあるチャットボットツールの中で代表的な3つのツールを比較しつつ、それぞれの特長を解説します。
| ツール名 | 日本語対応 | データ保存場所 | GPTの種類 | ノーコード対応 | コメント |
| Chatbase | ◯(回答可) | 独自クラウド(GCP) | GPT-3.5/4 | ◎ | 設定が簡単。無料枠あり |
| SiteGPT | ◯(精度高) | AWSベース | GPT-3.5 | ◎ | 検索重視のチャット型 |
| CustomGPT.ai | ◯(高精度) | 米国クラウド | GPT-4 | ◎ | 出典表示が丁寧。高性能 |
いずれのツールも、アップロードした自社データが外部に学習されることはありません。
自社ドキュメントだけを学習対象に限定できます。また、セキュリティやAPI連携の仕組みが整っており、企業利用にも最適です。
4-1.Chatbase:一番手軽な導入ツール
GoogleCloud(GCP)上にデータを保存し、GPT-3。5/4を利用したチャットボットを簡単に作成できます。
ノーコードUIでファイルをアップロードして即公開が可能。無料枠があり、試験導入がしやすいのは有難いです。日本語での応答は問題なく、文脈保持も良好らしいです。
料金は月額40ドルからです。既存のツール(Zendesk、Salesforce、Notion等)との直接統合することもできます。
生成AIに回答させたくない特定の問題は、人間にエスカレーションする機能もあります。
140か国9000社以上の企業で導入実績があります。自社サイトで、実際にチャットを公開していますので、日本語の応答速度や内容を確認できます。ChatbaseはSOC 2 Type IIおよびGDPRに準拠しており、セキュリティ面でも安心です。
4-2.SiteGPT:検索型に近い精度重視型
Chatbotというよりも「AI検索補助」型に近く、ユーザーの質問に対し正確な該当資料を提示する挙動に優れています。
日本語での回答精度が高いと言われています。出典ページやリンクを明示して回答するため、業務用にも安心です。
実際にデモページを公開しています。自分でチャットを使って、反応速度や日本語の応答速度を確認できます。
製品カタログやマニュアルなど、構造化された情報を多く持つ企業や出典明示が重要なFAQ対応業務には向いています。
無料枠はありませんが、7日間の無料トライアルがあります。
費用は月額39ドルから始められます。ユーザー側は、チャットとの対応に飽きた時は、ボタンを押すだけで、会話をシームレスに人間のエージェントにエスカレーションすることができます。
既存のツール(GoogleDrive、SharePoint、Dropbox等)との直接統合することもできます。
また、チャットボット側が、関心のある訪問者の詳細を取得し、潜在的なリードリストの作成を支援することができます。
4-3.CustomGPT.ai:品質最重視のチャットボット
こちらは、ビジネス用途を意識した生成AIです。第三者機関によって幻覚防止技術の精度が検証され、OpenAIやGoogleなどの大手企業を上回った高機能ツールです。
ノーコードでの設定にもかかわらず、高度なチューニングが可能で、回答ごとに参照した文書や出典のURLを丁寧に表示します。
セキュリティや外部API連携も充実しており、SOC-2タイプII、GDPR対応、データは完全に暗号化され、ファイルは保存されません
Microsoft Officeドキュメント、Googleドキュメントなど1400以上のファイル形式に対応しており、正確性と出典明示が最重視される税務、法律、製造業等で導入実績があります。
複数ドメインでサービス横断での検索もできます。月額99ドルからで、無料枠はありませんが、7日間の無料トライアルがあります。
こちらも実際にチャットを公開しています。自分で使ってみて、日本語の応答速度や内容を確認できます。
4-4.ツール選定の際に見るべきポイント
どのツールも、最終的には使用してチューニングしないと、検索と回答精度がどこまで出るか分かりません。
幸いにも、3つのツールには無料利用期間がありますので、導入前に以下の点はチェックした方が良いでしょう。
1)日本語対応の精度
これは自社で質問してくるユーザーの意味があいまいでも、適切に補完して回答を返せるかというところです。例えば、「プリンタが反応しません」に対して「印刷できない」とみなして正しい対処法を案内できるか。「最初どうすればいい?」など曖昧な聞き方に、「初期設定について正しく対処できるかということです。過去のFAQ等のデータが多数残っている場合、「最新版マニュアル」に基づく案内を優先できているかも確認しましょう。
2)「無回答」のケース
データ量が不十分な場合の「無回答」の場合に、どのような挙動になるのかは事前に確認が必要です。
設定により、情報が見つからない場合は無理に回答を生成させず、「該当情報が見つかりません」などと答える動作にすることもできます。このような素っ気ない表現ではなく、回答をどこまでカスタマイズできるのかも確認しましょう。
これにより、誤った推測や曖昧な回答を防ぎ、信用失墜リスクを避けられます。
関連文書を複数提示し、ユーザー自身に選ばせる設計ができるものもあります。この方式であれば、生成AIの提案から選択するという形式になるので、「無回答」を防ぎ、利用者からの信頼を担保できます。
3)セキュリティ
これは前項でも説明しましたが、自社データが保存されるクラウドが、信頼性の高いクラウドに保管されているか、データが転送中に暗号化されているか、各国の規制に対応できている
かということです。
海外のサービスの場合は、日本法人が存在するかというのも大事な確認ポイントです。
多くの企業担当者が不安を抱くのが、「自社のデータがOpenAIに学習されてしまうのでは?」という懸念です。実際、ChatGPT(無料版やChatGPTPlus)ではユーザーの入力内容を学習に利用することがあります。
一方で、Chatbase、SiteGPT、CustomGPT.aiのように、API経由でChatGPTを利用するツールでは、明示的に学習対象にしない設定が可能です。
OpenAI公式によれば、「OpenAI APIを通じて送信されたデータは、デフォルトでモデル学習に使用されない」と明記されています。
4)カスタマイズ性
回答の長さ、出典表示、URLリンクなど調整可能かという点です。
生成AI、とりわけChatGPTのようなモデルは「文脈に応じて自然な文を生成する能力」に長けていますが、逆にいえば「知らないことでもそれらしく答える」こともあります。
AI検索の実装においては、「正確であること」を重視した設定が不可欠です。
生成された回答だけでなく、出典となった文書名・URL・セクション名などを必ず表示させることで、ユーザーが内容の正しさを自分で確認できるようにします。
特にFAQやマニュアルに関する回答では、出典の提示がなければ現場では使いづらいという声も多くあります。
また、ホームページに組み込む時にどのような実装が可能なのかというのも確認しておきます。
具体的には、チャットボットのような吹き出し型だけでなく、「検索ボックス風に」埋め込めるのか?ということです。こういった実装方法はツールによって異なりますのであらかじめ確認しておきましょう。
ほぼすべての生成AI系チャットツールは、「画面の右下に出てくる吹き出し型」のウィジェットコードを提供しています。これは、HTMLやJavaScriptに慣れていないユーザーでも、コードを貼り付けるだけで導入できます。
一部のツールでは、検索ボックス風のUIをサイト上に組み込むことも可能です。
どのツールも、日本語回答の精度は実用水準に達しています。
いずれもノーコード対応で導入が可能ですが、管理画面まで日本語に対応しているかは確認できませんでした。しかし、翻訳ソフト等もあるので、運営者が1人でも即日導入可能なレベルだと思います。
以上は、2025年の上半期のデータです。生成AIツールは日進月歩で進化しており、非常に簡単に導入できるようになってきているのがわかります。
5.社内の情報管理体制とガイドラインの整備
生成AIを効果的に活用するには、AIに学習させる資料、ドキュメント等の質が大きく影響します。
生成AIツールの設定や機能だけでなく、AIに学習させる文書の整理も含め、社内の運用ルールの整備が重要になってきます。
ツール導入前に「どの文書・ドキュメントやマニュアルは業務で使えるか、使えないのか」の線引きをしておくことはとても大切です。
同時に、社内関係者全員に、生成AIがどのような資料に基づいて「トレーニング」されていて、自ずと限界があることも周知する必要があります。
特に、法律やルールが頻繁に変わる業種、制度変更の多い業界では、定期的に情報の内容を見直さなくてはなりません。運用ルールを最初から確立することが、誤った回答を防止する鍵となります。
6.導入後のチェックポイントと改善サイクル
生成AI検索やAIチャットボットは、導入後に完全な状態で、すぐに使い物になるというものではありません。
むしろ導入してからが本番といっても過言ではありません。精度やユーザビリティを向上させていくための、導入後の運用体制は不可欠です。
AIによるチャットボットの回答や検索では、「正確に」「素早く」目指す情報にたどり着けるかが成否を分けます。
生成AI活用の効果を最大化するための実践的な運用ポイントは以下の通りです。
6-1.利用ログの収集と分析
ここで取り上げた3つの生成AIサービスは、ユーザーの入力や応答履歴を記録するログ機能が備わっています。導入後は、「ユーザーが何を尋ねているのか?」を把握することが最優先です。
たとえば以下のようなログを分析しましょう:
・よくある質問ワード(例:「導入費用」「初期設定」「エラー時」など)
・入力されたが回答できなかった質問(無回答ログ)
・間違った情報を返した履歴(誤答ログ)
これにより、FAQやマニュアルそのものに改善すべき点が見えてきます。
6-2.無回答・誤答ログをもとに改善する
「無回答だった質問」や「意図しない回答が返った質問」は、FAQやマニュアルの“穴”を示しています。
実際に寄せられた質問ベースを起点に、FAQの追加・修正、マニュアル構成を最適化しましょう。
その後、更新後のFAQ・マニュアルを再取り込み、生成AIに再インデックス化して、回答精度を上げていきます。
似たような質問がたくさん来ており、FAQやマニュアルの穴を簡単に埋めることができれば、短期間に生成AIの導入効果を上げることができます。
しかし頻度は少ないけれども、ユーザから思いもかけないような質問が来ていることもあります。
ユーザーの検索意図を読み取って、営業のツールやマニュアル、販売戦略などに生かすことができないかを考えましょう。
6-3.一定の回答精度に達したら「限定チャット」を「公開」へ
初期導入段階では、検索型AIを社内用または一部ユーザー向けに限定するケースが一般的です。
しかし、例えば、以下のような条件が揃ったら、問い合わせフォームやヘルプページにチャット型で導入するという拡張も現実的になります。
- 無回答率が一定程度に低下(例:10%以下)
- FAQの網羅率が8〜9割以上
- 更新フロー・再インデックスが社内に定着した
このように段階的に導入を行うことで、リスクを抑えつつユーザー体験を強化できます。
まとめ
調べてみて、生成AIを使ったチャットボットや検索システムは、もはや技術的に「特別なもの」ではないことがわかりました。現在あるPDFやWebページだけでも試験導入は可能です。
しかし、B2Bでの活用においては、単なる利便性以上に、正確性・安全性・管理運用面が問われます。自社FAQ、マニュアル、製品資料など、「現時点で持っている情報資産の整理」が出発点だと感じます。
また、生成AIを使ったチャットボットは全てを解決してくれる魔法の杖ではありません。
重要なのは、「完璧なものを最初から目指す」のではなく、利用者の声を活かして精度を高めるプロセスを回すことです。
生成AIは、使えば使うほど「賢くなる仕組み」を備えています。まずは小さく始めて、確実に改善し続ける運用体制こそが成功の鍵となります。
[参考資料]ベクトル検索(Vector Search)とは? キーワード検索との違い
Chatbot Knowledge Base 101: From Set-Up to Success
Chatbase AI agents for magical customer experiences









